
6 min para ler
CESAR .
Publicado em: 08 de dezembro de 2022
Tecnologia
Data Augmentation: Como transformar dados já existentes em novas fontes de informação

Por Marianna Severo, Data Scientist e Vitor Casadei, Senior Technical Data Scientist do CESAR.
A Data Augmentation compreende um conjunto de técnicas que têm como objetivo melhorar a qualidade dos conjuntos de dados, de forma a melhorar o desempenho dos modelos de aprendizado, principalmente daqueles que mais sofrem com o overfitting, um problema relacionado à perda da capacidade de generalização do aprendizado dos modelos para amostras não vistas durante o treinamento. Para isso, ela se aproveita dos dados já obtidos para a geração de novas amostras [1].
É importante destacar que essas técnicas visam não somente aumentar o volume de dados, mas também trazer maior diversidade para os conjuntos gerados. Uma vez que no mundo real um mesmo fenômeno pode ter diferentes características, precisamos trazer essa diversidade para os dados, visando ajudar os modelos a tornarem-se invariantes a elas [2].
Como funciona a Data Augumentation?
A DA pode ser aplicada a diferentes tipos de dados, como tabulares, imagens, textos e áudios. E existem duas abordagens básicas: a distorção (Warping), que transforma os dados existentes, mas preserva seu rótulo; e a síntese (Oversampling), que gera amostras sintéticas a partir do aprendizado extraído dos dados. Além disso, ela pode ser empregada durante o treinamento do modelo (Online) ou para a criação de um conjunto aumentado previamente (Offline) [2].
Data Augmentation para Imagens
Com relação à DA para imagens, existe uma vasta variedade de técnicas na literatura. Mas o que é uma imagem? Ela pode ser vista como uma matriz de elementos que representam intensidades, chamados de pixels, que podem estar em diferentes intervalos de valores, como números inteiros de 0 a 255 ou números de ponto flutuante de 0 a 1. Uma imagem possui largura, altura e canais. E dois tipos comuns são as que estão na escala de cinza (1 canal) e as RGB (3 canais).


Fontes: Foto por Lukas Godina on Unsplash; foto por Ludemeula Fernandes on Unsplash.
*A imagem da esquerda está em escala de cinza e a imagem da direita está em RGB.
Existem diversas propostas de organização das técnicas de DA para imagens. Uma proposta interessante apresentada em Yang et al. [3] e observada na Figura 01, as categoriza em abordagens básicas e avançadas. As primeiras envolvem métodos de processamento de imagens e são consideradas de mais simples implementação (ramo à esquerda na Figura 04). As segundas costumam utilizar modelos de aprendizado profundos e podem ser mais complexas de se implementar e aplicar (ramo à direita na Figura 02) .
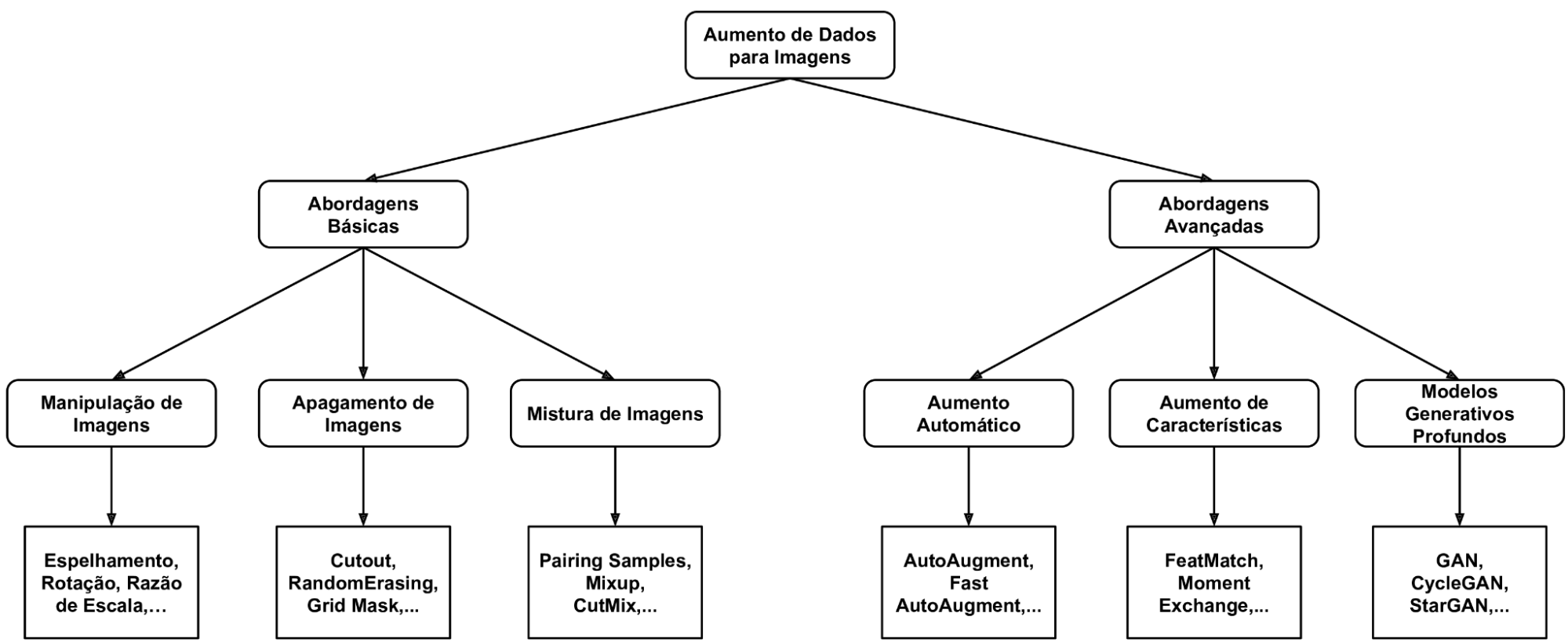
Fonte: Adaptado de Yang et al. [3].
Quais os principais exemplos dessas abordagens?
Técnicas Tradicionais
As técnicas tradicionais têm como objetivo produzir amostras que ajudem os modelos a se tornarem invariantes a características, como: localização no espaço, ângulo de visão, ruídos, iluminação, entre outras. Tornar-se invariante significa apresentar resultados que são independentes das variações dessas características. Alguns exemplos são as transformações geométricas (Figura 03), como translação, rotação e escala, e as fotométricas (Figura 03), como brilho e contraste.



Figura 03: Exemplos de DA tradicionais
Translação (a), Ruído Salt & Pepper (b) e Contraste (c)
Fonte: Adaptado de Foto por Adison Ferreira em Unsplash.
Image Erasing
Técnicas de Image Erasing (apagamento de imagem, em português) removem uma ou mais sub-regiões da imagem, substituindo-as por valores constantes ou aleatórios. Elas visam gerar dados que ajudem os modelos a se tornarem invariantes a oclusões, incentivando-os a aprender características mais descritivas, ao invés de atributos específicos que nem sempre estarão presentes [2]. Um exemplo é a Random Erasing (apagamento aleatório, em português) [4].

Fonte: Adaptado de Zhong et al (4).
Na figura, observamos diferentes abordagens de aplicação da técnica de Random Erasing. Na primeira linha, há exemplos de apagamentos que podem ocorrer em qualquer região da imagem, chamados de sensíveis à imagem. Na segunda linha, vemos apagamentos aplicados somente dentro dos retângulos (bounding boxes) que delimitam os cavalos, chamados de sensíveis ao objeto. Por fim, na terceira linha, há exemplos de apagamentos que podem ser aplicados tanto sobre toda a imagem como apenas sobre os bounding boxes.
Meta-Aprendizado
Tem como objetivo aprender automaticamente quais são as melhores transformações para um determinado conjunto de dados. Um exemplo bem conhecido é o AutoAugment [5], que é uma abordagem de aprendizado por reforço que busca uma política ótima de aumento, dado um conjunto de transformações e níveis de distorção.
Modelos Generativos Profundos
Conjunto de técnicas que têm como objetivo, a partir do aprendizado extraído sobre um conjunto de dados, gerar novas amostras que possuam características semelhantes às presentes nele. Por exemplo, um modelo generativo pode ser treinado com um conjunto de imagens de faces de pessoas e aprender a gerar novas imagens de pessoas que não estão no conjunto original, mas que têm características parecidas, como a cor do cabelo, a pose do rosto, o uso de óculos, entre outras. Um exemplo famoso são as Redes Adversárias Generativas (do inglês, Generative Adversarial Networks – GANs) [2].
Principais desafios em Data Augmentation
Embora diversos desenvolvimentos já tenham sido alcançados, ainda existem uma série de desafios e caminhos a serem explorados dentro do universo de DA. Algumas questões envolvem:
- Tamanho final da base de dados aumentada;
- Combinação entre diferentes técnicas;
- Compreensão teórica do funcionamento das técnicas;
- Recursos computacionais e complexidade dos métodos;
- Técnicas voltadas para a melhoria da robustez de modelos;
- Qualidade das amostras geradas;
- Desenvolvimento de softwares que implementam técnicas avançadas;
- Tamanho/diversidade mínimos ideais para as técnicas de DA serem efetivas.
REFERÊNCIAS
[1] Data Augmentation in Python: Everything You Need to Know. 21 de julho de 2022. Disponível em: https://neptune.ai/blog/data-augmentation-in-python. Acesso em: 12 de outubro de 2022.
[2.] Shorten, Connor, and Taghi M. Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of big data 6.1 (2019): 1-48.
[3] Yang, Suorong, et al. Image Data Augmentation for Deep Learning: A Survey. arXiv:2204.08610 (2022).
[4] Zhong, Zhun, et al. Random erasing data augmentation. AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.
[5] Cubuk, Ekin D., et al. AutoAugment: Learning augmentation strategies from data. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.